
数据与统计资料
统计学 : 是搜集、分析、表述和解释数据的科学与艺术。
数据 : 是为了描述和解释所搜集、分析、汇总的事实和数字。
个体:搜集数据的实体
变量:个体中感兴趣的那些特征
观测值:(对每个个体的每一变量搜集测量值,从而得到数据。)对某一特定个体得到的测量值集合称为一个观测值。
名义尺度:用来识别个体属性的标记或名称 (可以使用数值代码及非数字的标记)
顺序尺度:具有名义尺度的性质,并且数据的顺序或等级的意义明确。
间隔尺度:具有顺序尺度的性质,并且可以按某一固定测量单位表示数值间的间隔、
比率尺度:具有间隔尺度的性质,并且两个数值之比是有意义的。(比率尺度需要有一个零值)
分类变量:用分类型数据(名义尺度、顺序尺度)表示的变量
数量变量:用数量型数据(间隔尺度、比率尺度)表示的变量
截面数据:相同或近似相同的同一时点上搜集的数据
时间序列数据:几个时期内搜集的数据
数量型数据可以是离散的也可以是连续的。
1、度量可数事物多少的数量型数据是离散(5分钟内接到的电话个数)
2、度量不可数事物多少的数量型数据是连续(体重或时间)
总体:一个特定研究中所有个体组成的集合。
样本:总体的一个子集。
描述统计学I:表格法和图形法
分类型数据汇总
频数分布(frequency distribution) : 在几个互不重叠组别中的每一组项目的个数(即频数)
相对频数(relative frequency distribution) : 属于该组别的项目个数占总数的比例
对于一个有n个感测值的数据集 , 组的相对频数 = 组的频数 / n
百分数频数(percent frequency distribution) : 相对频数乘以100
相对频数分布 : 每一组相对频数数据的表格汇总 ,百分数频数分布 : 每一组百分数频数数据的表格汇总
条形图:用来描绘已汇总的分类型数据的频数分布、相对频数分布或百分数频数分布。
对于分类型数据,应将这些长条分隔开,以强调每一组是相互独立的事实。

饼形图:另一种描绘分来型数据的方法,不是呈现对比的百分比的最佳途径。
数量型数据汇总
确定频数分布组时的三个步骤:
1、确定互不重叠的组数
2、确定每组的宽度
3、确定组限
组数:一般性原则,使用5~20个组。
组宽:每组宽度相同,较大的组数意味着较小的组宽,反之亦然。从确定数据的最大值和最小值开始!
近似组宽 =( 数据最大值 – 数据最小值 )/ 组数
组限:必须使每一个数据值属于且只属于一组。相邻两组的下组限之差就是组宽。
下组限:被分到该组的最小可能的数据值,上组限:被分到该组的最大可能的数据值。
组中值:下组限和上组限的中间值。
开口组:只有一个下组限或者上组限的组。(如10或10以上,来简化频数分布)

相对频数与百分数频数 与分类型数据同理。
打点图:横轴是数据的值域,每一个数据由位于横轴上的点表示。

直方图:邻近的长方形是互相连接的,与条形图不同,直方图相邻组的长方形之间没有自然的组隔。(有些离散的数量型数据,各纵条之间有间隔是合适的)

累积频数分布:小于或等于每一组上组限的数据项个数,而不是表示每一组的频数。

茎叶显示:同时用于显示数据的等级顺序和分布形状的图形显示。(根据每一个叶值使用一位数表示的惯例)

两个变量的数据汇总
交叉分组表:一种汇总两个变量数据的方法。提供了变量间关系的深刻含义。

辛普森悖论:从两个或多个单独的交叉分组表得到的结论与一个综合的交叉分组表数据得到的结论可能截然相反。依据综合和未综合数据得到相反的结论被称为辛普森悖论。
当交叉分组表包含综合数据时,应该审查时候存在可能影响结论的隐藏变量。


散点图:对两个数量变量可关系的图形表述。
趋势线:显示相关性近似程度的一条直线。(正相关,没有明显相关,负相关)

复合条形图:对已汇总的多个条形图同时显示的一种图形显示方式。

结构条形图:每一个长条被分解成不同颜色的矩形段。


总结:
条形图:用于展示分类型数据的频数分布和相对频数分布。
饼形图:用于展示分类型数据的相对频数分布和百分数频数分布。
直方图:用于展示数值型数据在一个区间组集合上的频数分布。
打点图:用于展示数值型数据在整个数据范围内的分布。
茎叶显示:用于展示数值型数据的等级顺序和分布形态。
散点图:用于展示两个数量变量的相关关系。
趋势线:用于近似散点图中数据的相关关系。
复合条形图:用于两个变量的比较。
结构条形图:用于比较两个分类变量的相对频数和百分数频数
描述统计学II:数值方法
如果数据来自样本,计算的度量称为样本统计量
如果数据来自总体,计算的度量称为总体参数
样本统计量称为是相应总体参数的点估计量
一、位置的度量
1.平均数
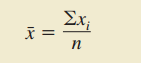 (样本平均数)
(样本平均数)
 (总体平均数)
(总体平均数)
2.加权平均数 (对观测值赋予显示其重要性的权重)
 (Wi–第i个观测值的权重)
(Wi–第i个观测值的权重)
3.中位数
1、将数据按升序排序
2、对奇数个观测值,中位数是中间的数值。
3、对偶数个观测值,中位数是中间两个数值的平均值。
4.几何平均数(常用于确定连续时期的平均变化率)
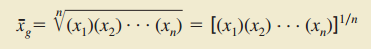
5.众数 (出现次数最多的数据)
如果数据中正好有两个众数,我们称数据集是双众数,
如果在数据中众数超过两个,我们称数据集是多众数。
6.百分位数
第P百分位数:至少有P%的观测值小于或等于该值,且至少有(100-P)%的观测值大于或等于该值。
1、把数据按升序排列。
2、计算指数i, 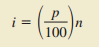 (p为所求的百分位数,n为观测值的个数)。
(p为所求的百分位数,n为观测值的个数)。
3、(a)若i不是整数,则向上取整。(b)若i是整数,则第p百分位数是 第i项 和 第i+1项 数据的平均值。
7.四分位数(将数据划分为四部分)
Q1 = 第一四分位数,或第25百分位数
Q2 = 第二四分位数,或第50百分位数(也是中位数)
Q3 = 第三四分位数,或第75百分位数
二、变异程度的度量 (离散程度)
1.极差
极差 = 最大值 – 最小值
2.四分位数间距(第三四分位数Q3与第一四分为数Q1的差值)
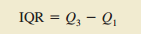
3.方差(较大的方差显示其变异程度越大)
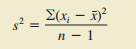 (样本方差,总体方差的无偏估计)
(样本方差,总体方差的无偏估计)
![]() (总体方差)
(总体方差)
4.标准差
样本标准差 ![]()
总体标准差 
5.标准差系数

三、分布形态、相对位置的度量以及异常值的检测
1.分布形态
偏度 : 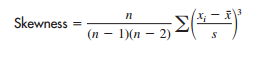
对于左偏的数据,偏度是负数;对于右偏的数据,偏度是正值,如果数据时堆成的,则偏度为0。

2.Z-分数(标准化数值,对数据集中观测值相对位置的度量)
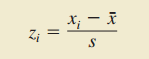 (能被解释为xi与平均数x的距离是Zi个标准差)
(能被解释为xi与平均数x的距离是Zi个标准差)
3.切比雪夫定理(与平均数的距离在某个特定个数的标准差之内的数据值所占比例)
与平均数的距离在Z个标准差之内的数据项所占比例至少为  , Z是大于1的任意实数
, Z是大于1的任意实数
至少0.75或75%的数据值与平均数的距离在z=2个标准差之内
至少0.89或89%的数据值与平均数的距离在z=3个标准差之内
至少0.94或94%的数据值与平均数的距离在z=4个标准差之内
4.经验法则(数据集被认为近似于对称的峰形或钟形分布)
大约68%的数据值与平均数的距离在1个标准差之内。
大约95%的数据值与平均数的距离在2个标准差之内。
几乎所有的数据值与平均数的距离在3个标准差之内。
5.异常值检测
下限 = 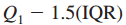
上限 = 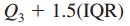
四、五数概括法和箱形图
(1)最小值
(2)第一四分位数
(3)第二四分位数(中位数)
(4)第三四分位数
(5)最大值
1.箱形图

五、两变量间关系的度量
1.协方差
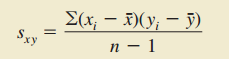 (样本协方差)
(样本协方差)
 (总体协方差)
(总体协方差)

协方差为正值,表示x和y存在正的线性相关。
2.相关系数
 (样本数据)
(样本数据)
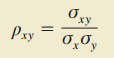 (总体数据)
(总体数据)
如果数据集中所有的点都在一条斜率为正的直线上,则样本相关系数的值为+1;x和y之间存在一个完全正线性相关;

 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫










最新评论